

Contexte
on a reçu un petit projet qui consistait d'un 'rebranding' du client. Comme nous travaillons avec beaucoup de clients industriels et automobiles, nous travaillons souvent avec des inventaires considérables.
Dans ce cas particulier, le client avait quelque 11,782 images dans lesquelles des objets physiques étaient placés sur un fond de papier (plastique ?) sur lequel était imprimé son logo. Malheureusement, comme ils étaient en train de faire un rebranding, nous avons été chargés de trouver une solution pour retirer l'ancien fond / logos.
La Recherche des Options
Sous-traitance
Ma première idée était d'aller chercher les services existants qui pourraient offrir une solution. Comme il s'agissait d'un travail à forte intensité de main-d'œuvre, j'ai tout de suite pensé à des services du type
Fiverr
Upwork
Reddit (r/slavelabour)
MTurk
TaskRabbit
En gros, tout ce qui me permettrait de louer le projet à un entrepreneur étranger. J'ai aussi directement posté le travail sur les forums de Reddit pour voir quel genre de prix je pourrais obtenir.
J'ai obtenu une gamme de prix assez large, mais en général, je regardais autour de 0,40 $ US par image. Pas terrible mais pas génial, étant donné que j'avais presque 12 000 images à traiter.
Services
Ensuite, j'ai décidé de chercher "supprimer les images de fond" pour voir ce que Google trouverait. À ma grande surprise, il y avait quelques entreprises qui proposaient des solutions plus automatisées basées sur la technologie de l'IA.
J'ai fini par faire des recherches sur quelques entreprises et je me suis concentré sur celles qui avaient des capacités d'API :
- Supprimer.bg
- Slazzer
- Déménagement.ai (marqué - lire mes notes ci-dessous)
- JumpStory (pas d'option API)
- Adobe Spark
Ces prix n'étaient pas mauvais. Remove.bg et Slazzer étaient mes deux meilleures options puisqu'ils avaient des démos dont on pouvait essayer et ensuite voir les résultats. Ils avaient également des instructions API claires et bénéficiaient d'un support solide de la communauté en ligne.
J'ai fini par essayer JumpStory aussi (je me suis inscrit à l'essai gratuit), mais j'ai été déçu de trouver que leur outil était lent et qu'il manquait une option d'API. J'ai fini par annuler avant que le paiement n'ait été effectué.
Une remarque importante à propos de Removal.ai. Au début ils étaient mon option préférée, principalement en raison de leur prix. Leur site semblait également très propre et légitime et leur technologie semble être basée sur le même modèle d'IA que celui de Remove.bg et de Slazzer. Ils avaient aussi le même outil de test qui fonctionnait bien.
Cependant, en creusant un peu plus, des signaux d'alerte ont commencé à apparaître. Dans le bas de page, la section "Presse" ne va nulle part, alors que Slazzer a fait les gros titres il y a quelques mois avec leur lancement réussi sur ProductHunt.com et PitchGround.com.
J'étais surtout intéressé par leur API. Leur site dit que je peux essayer 50 images gratuitement, mais je n'ai trouvé aucune instruction ni aucun endroit pour créer une clé API
J'ai fini par réaliser que le texte décrivant leur API était à peu près tiré de Remove.bg qui contient des instructions claires sur la façon de créer et d'utiliser une clé API avec leur service.
Tout cela pour dire que Removal.ai a rapidement disparu de ma liste.
Remove.bg était en première position et bien documenté avec de solides supporteurs, cependant, Slazzer était simplement moins cher pour la plupart des images avec lesquelles je devais travailler.
J'étais assez décidé, mais j'ai décidé de creuser juste un peu plus.
Commentaires de la communauté
De retour sur Reddit, j'avais posté un fil de discussion séparé pour obtenir les réactions de la communauté et voir si elle avait des suggestions.
Les gens m'envoyaient des messages avec des tarifs aussi bas que 2,000 dollars US pour faire le lot à la main. D'autres me suggéraient certaines des options d'IA que j'avais énumérées ci-dessus. Quelques commentaires ont cependant suscité mon intérêt. Ils ont mentionné la possibilité de louer les services d'un programmeur pour écrire le travail à ma place et exécuter les modèles d'IA directement, sans passer par les API payantes.
"Mais attendez", me suis-je dit, "Je suis programmeur !". Et c'est ainsi qu'est né un profond trou de lapin qui a consommé trois nuits de sommeil.
Les bonnes choses
1. Renseignements techniques
J'ai commencé à regarder les projets open source pour voir ce que je pouvais trouver pour "l'élimination de l'arrière-plan de l'IA". J'ai fini par me retrouver sur GitHub. Rétrospectivement, il aurait été beaucoup plus logique de commencer sur GitHub mais, peu importe.
J'ai examiné quelques projets et j'ai fini par regarder de près U-2-Net-Demo de shreyas-bk, car il n'utilisait pas d'API tierce partie (payante) et était bien documenté. De plus... ils sont arrivés en deuxième position dans ma recherche sur GitHub, donc il y a ça.
La repo "démo" est en fait un exemple documenté de l'utilisation de la repo "U-2-Net". Au début, c'était un peu confus pour moi car il y avait beaucoup de nouvelles technologies avec lesquelles je n'avais jamais joué auparavant. Finalement, j'ai compris la pile technologique :
- Google Colab (Colaboratoire)
- Carnet Jupyter
- Python
- Tensorflow
- GitHub
Parmi les technologies ci-dessus, je n'avais vraiment qu'une expérience limitée avec GitHub et Python. Je n'avais même jamais entendu parler de Jupyter Notebook et n'avais que vaguement entendu parler de Colab et de Tensorflow.
La première chose à noter était l'extension .ipynb sur les fichiers de la pension. Je n'avais aucune idée de cette extension, alors j'ai fait une recherche rapide et je suis tombé sur Jupyter Notebook.
Je suis encore très novice dans tout cela (n'hésitez pas à me laisser des commentaires pour me corriger) mais je crois comprendre qu'il s'agit d'un environnement de développement qui fonctionne comme une sorte de machine virtuelle. Il existe une option pour une interface basée sur le web qui semble englober du code, un simple système de fichiers et un pseudo système d'opération.
La raison de l'extension ipynb est que le projet s'appelait auparavant "IPython Notebook". Le nom a été changé en "Jupyter Notebook" et le Colab de Google supporte simplement ce format de fichier.
Ce qui est bien avec Google Colab, c'est que, comme c'est un produit Google, il s'intègre parfaitement à Google Drive. C'est devenu très pratique quand il s'est agi d'exporter les fichiers de mon projet de test vers un espace qui me permettait de télécharger des milliers de fichiers à la fois.
2. Mise en place de mon projet
Une fois que j'ai mieux compris ce que je regardais, la démo de U-2-Net a fait beaucoup plus de sens.
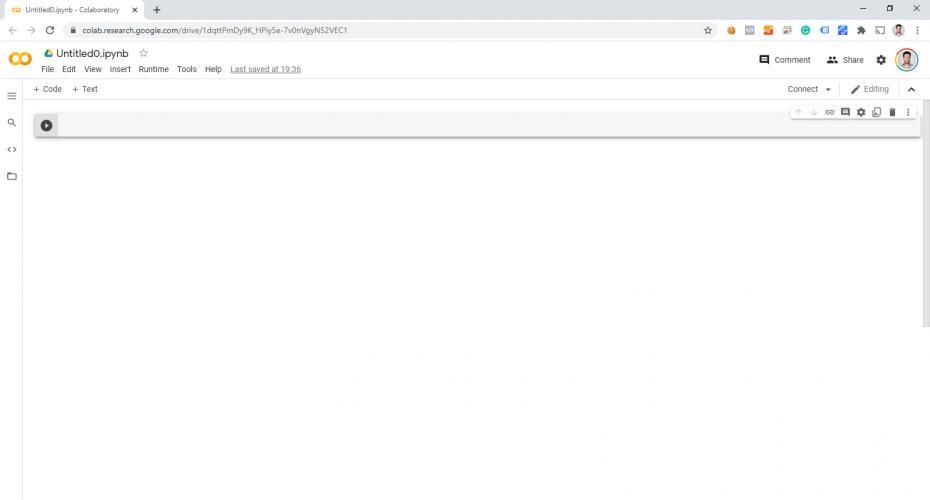
J'ai ouvert un compte sur Colab et j'ai ouvert un fichier vierge :
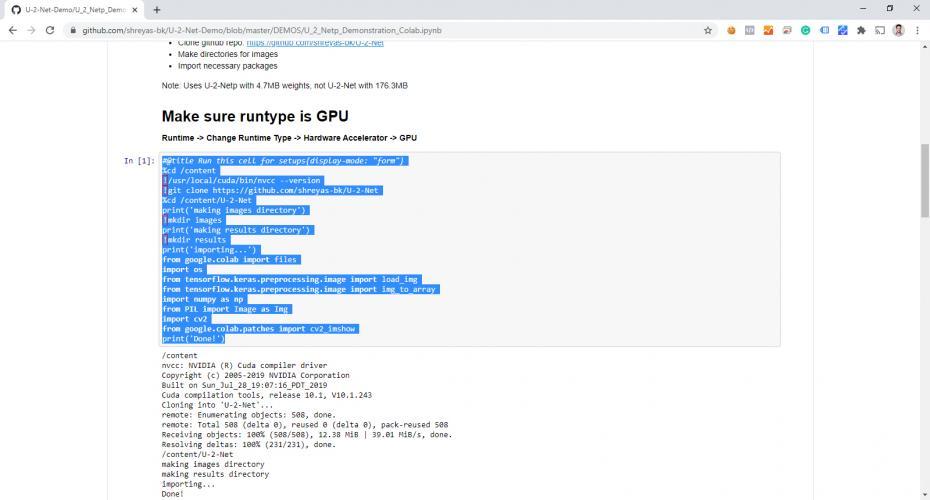
J'ai ensuite copié le code du repo (démo) :
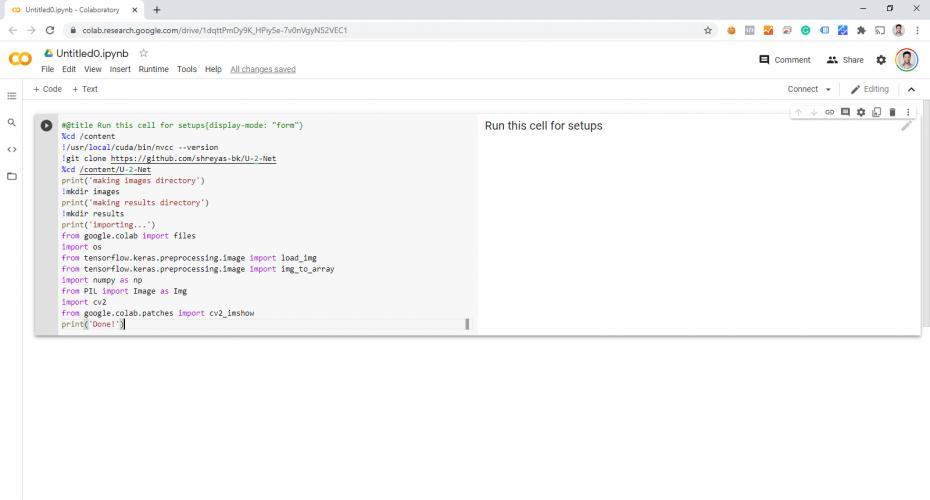
Et l'a collé dans le premier bloc de code sur Colab :
Répétez l'opération pour les autres blocs de code :

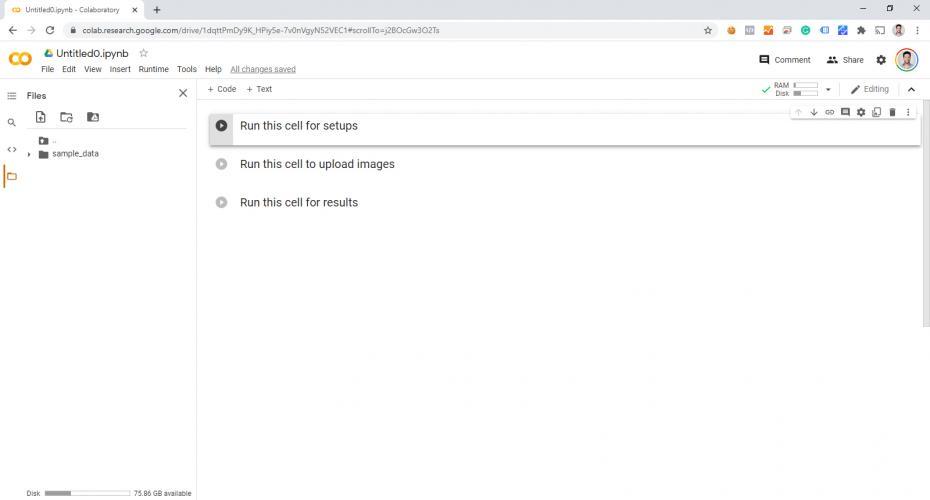
Exécutez le premier extrait de code pour effectuer la configuration initiale (clonage à partir de GitHub). Notez les fichiers à gauche :
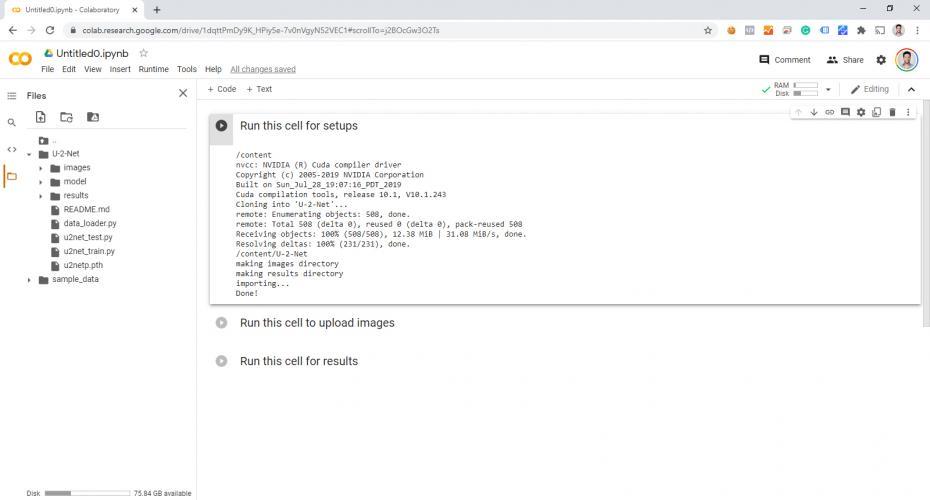
Pour mes besoins, j'ai également connecté mon Google Drive en cliquant sur l'icône "Drive" en haut à gauche :
Notez les dossiers "Drive" > "MyDrive" apparaissant dans la structure des fichiers à gauche :
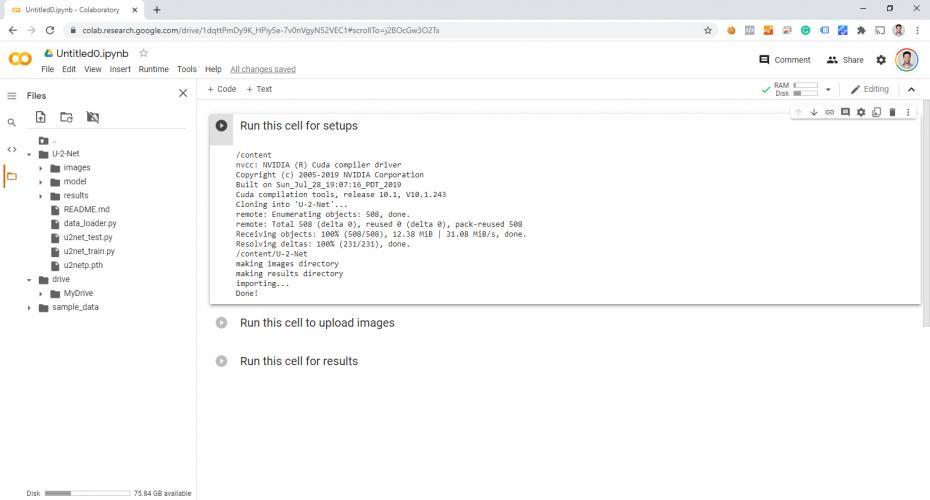
Puisque nous importons autant d'images, j'ai simplement téléchargé (uploaded) mes fichiers dans le dossier "images" (en les faisant glisser de mon ordinateur, au lieu de les sélectionner un par un via l'outil de démo) :
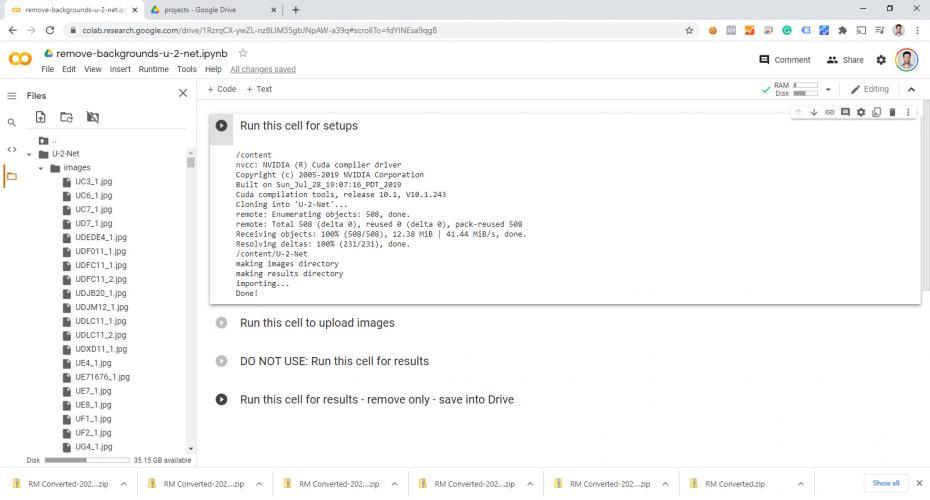
J'ai également copié le script original "Exécuter cette cellule pour les résultats", puis je l'ai modifié pour mes besoins.
Le script original a non seulement supprimé l'arrière-plan, mais il a aussi créé une image de sortie d'exemple à quatre cellules qui montre tout ce qu'il a fait. À la place, j'ai supprimé le code qui fait autre chose que d'isoler et d'effacer l'arrière-plan.
J'ai également modifié la sortie pour copier simplement l'image résultante, avec le fond supprimé, dans un dossier au lieu de l'afficher. Lors de ma première exécution, j'ai appris à mes dépens que mon ordinateur n'était pas très heureux d'essayer d'afficher des milliers d'images saisies.
Depuis que j'ai connecté mon compte Google Drive, j'ai pu sortir les fichiers directement sur Drive afin de pouvoir les télécharger tous sous forme de fichier .zip :
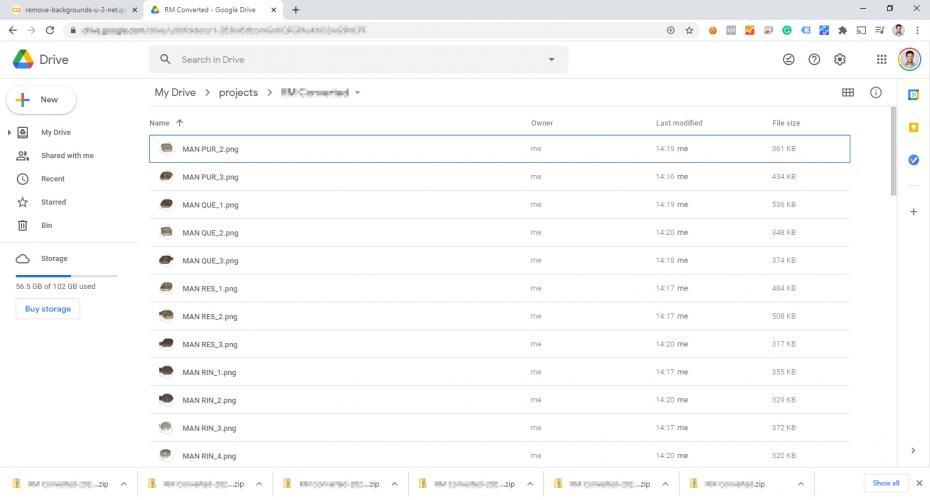
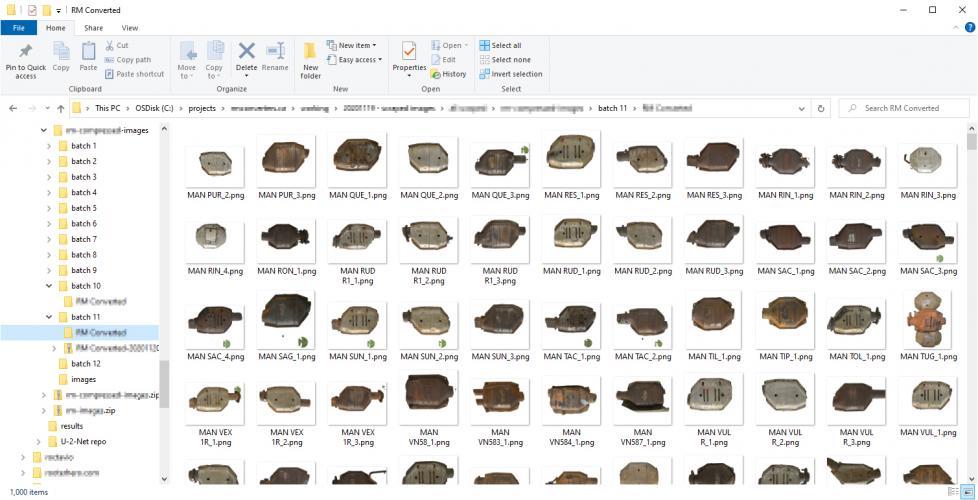
Et voilà ! J'ai réussi à convertir 11,782 images en utilisant l'IA gratuitement. Bien que l'option gratuite de Colab ait ses limites, cette opération n'a même pas approché les limites de mon compte.
Notes Finales
Il faut aussi noter que je n'ai pas pu faire la totalité des 11,782 lots en un seul coup. Je faisais des lots de 1,000 images à la fois et j'ai dû à chaque fois vider Colab et rattacher Google Drive. Il y avait également un certain décalage entre le téléchargement des fichiers .zip, le vidage du dossier et la synchronisation des différences sur le système de fichiers de Colab.
Finalement, je me suis rendu compte que la meilleure chose à faire était de "renommer" le dossier "images" du côté de Colab et de recréer le dossier "images" pour télécharger le prochain lot d'images. J'ai trouvé cela plus rapide et plus simple que d'essayer de recharger Colab.
J'ai également remarqué que le fait de renommer le dossier de sortie du côté Colab mettait à jour le côté Google Drive beaucoup plus rapidement que l'inverse. C'était un autre petit contournement pour accélérer le traitement, au lieu d'attendre que le système de fichiers de Colab rattrape son retard ou d'essayer de recharger Colab et de devoir reconnecter le lecteur après chaque lot.
Le résultat n'était pas non plus parfait. J'ai fini par devoir parcourir un certain nombre de fichiers dans Photoshop pour supprimer les artefacts restants que l'IA n'avait pas complètement capturés. Il faut quand même noter que cette option ne semblait pas être pire que ce que les algorithmes payants offraient ET que cette méthode faisait quand même 95% du travail.
D'un point de vue personnel, je suis également heureux d'avoir eu la chance de jouer avec Google Colab et Tensorflow, même si je n'ai pas vraiment fait de "programmation d'IA".
